【AWS_43】AWS Lambdaを検証する

Lambdaはユーザーが開発したコードを実行環境を管理せずに実行できるサービスとあります。
私は開発経験がないので理解が合っているかわかりませんが、開発したコードを実行するには、何かしらの実行環境をインストールする必要があると認識しています。現時点では、Lambdaはいろいろな実行環境がまとまっているマネージドサービスと認識しています。
机上の勉強だけでは理解が進まないので参考サイトを参考に検証してみたいと思います。
具体的には、S3バケットにオブジェクト(テキスト)がアップロードされるとLambda関数が実行されることを検証してみます。
今回の記事でPythonのコードを記載していますが、私はPythonを書けないため参考サイトの情報をそのまま利用させていただいてます。
今度こそ理解する!俺式Lambda入門
https://dev.classmethod.jp/articles/lambda-my-first-step/
目次
(事前準備)S3バケットの作成
Lambda関数の検証を実施するにあたりS3バケットが必要となります。
事前に作成しておきます。
今回は、20250813-bucketという名前でS3バケットを作成しています。作成手順は以下記事にまとめていますので参考にしてください。
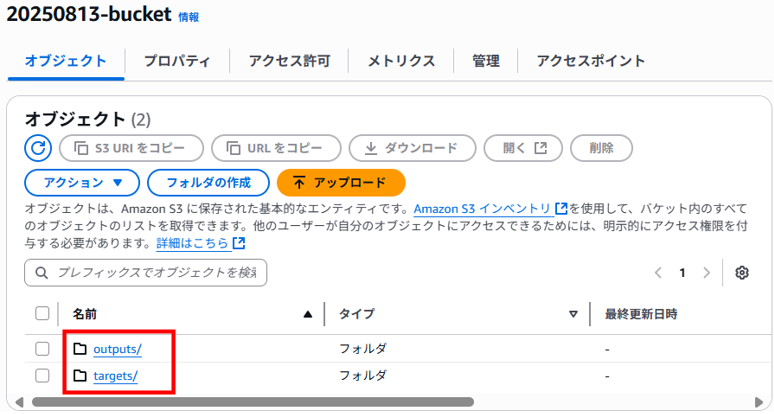
さらに作成したS3バケット「20250813-bucket」の中に「targets」というフォルダと「outputs/targets」という2階層のフォルダも後で使うので作成しておきます。
Lambda関数の作成
Lambda関数自体の作成
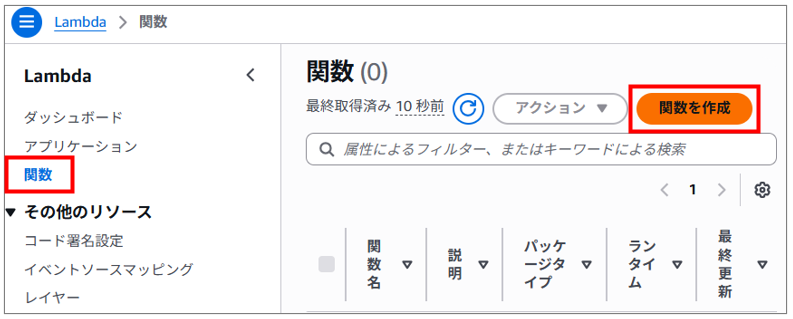
AWSマネジメントコンソールで「lambda」を検索します。
左ペインの関数をクリックし、画面右上の「関数の作成」をクリックします。
関数の作成は、「一から作成」を選択します。

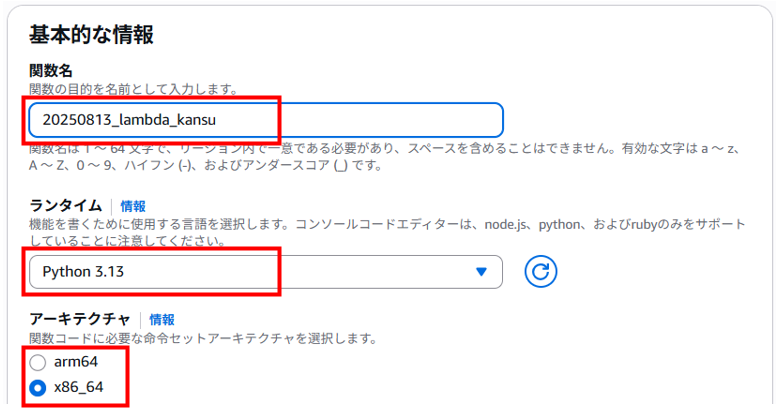
基本的な情報は、以下を入力、選択します。
・関数名:任意の関数名(20250813_lambda_kansu)
・ランタイム:Python3.13
・アーキテクチャ:x86_64
アクセス権限は、以下を入力、選択します。
・実行ロール:AWS ポリシーテンプレートから新しいロールを作成
・ロール名:任意のロール名(20250813_lambda_Role)
・ポリシーテンプレート – オプション:何も選択しない
その他の構成は、デフォルトのままで「関数の作成」をクリックします。
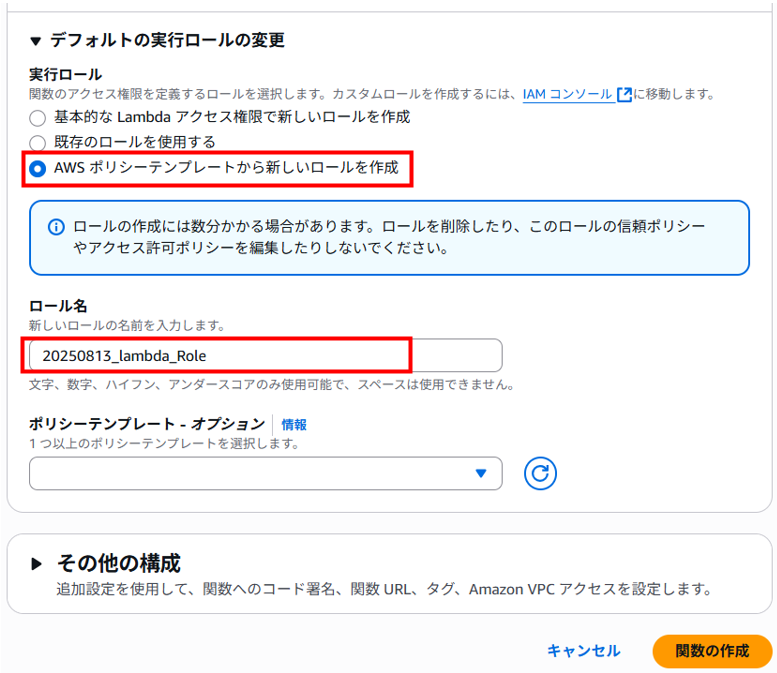
「Getting started」画面が表示された場合は、「Dismiss」をクリックして閉じます。
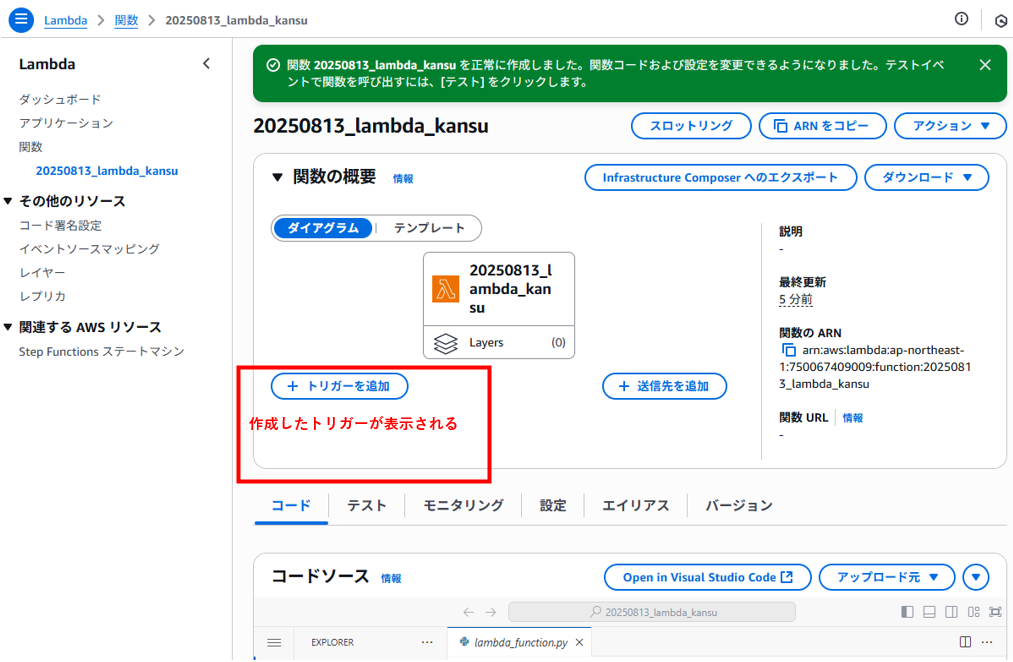
Lambda関数が作成されました。関数の中身はないですが箱だけできたイメージです。
左の赤い部分には作成したトリガーが表示されます。
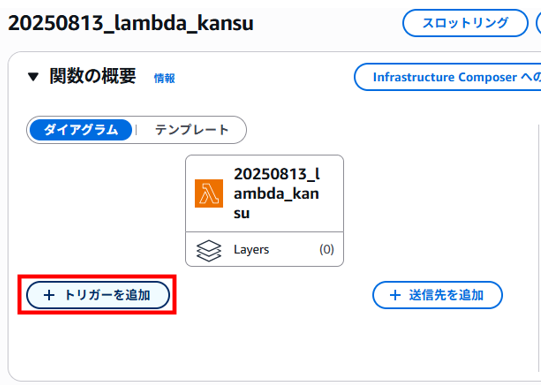
トリガーの追加
Lambda関数へトリガーを追加します。今回はS3バケットへオブジェクト(テキスト)がアップロードされたらLambda関数が実行されるよう設定していきます。
「トリガーを追加」をクリックします。
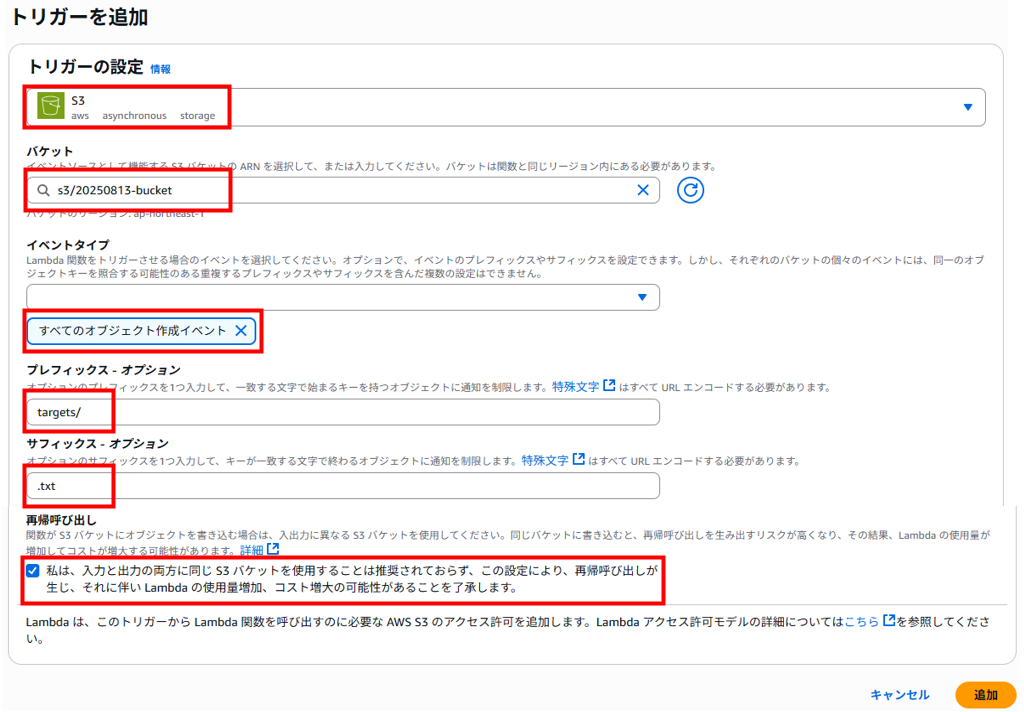
トリガーを追加画面で以下を入力、選択し、「追加」をクリックします。
・トリガーの設定:S3
・バケット:事前に作成したバケット
・イベントタイプ:すべてのオブジェクト作成イベント
・プレフィックス – オプション:任意のS3バケット内のフォルダ
・(今回 targets/ としましたがS3バケットには targets/ フォルダは作成しておりません)
・サフィックス – オプション: .txt (**.txtがアップロードされたらトリガーが実行される)
・再帰呼び出し:チェックします
トリガーが追加されました。
Lambda関数のコードを編集
次にコードを編集します。 関数名の下にある「Layers」をクリックします。
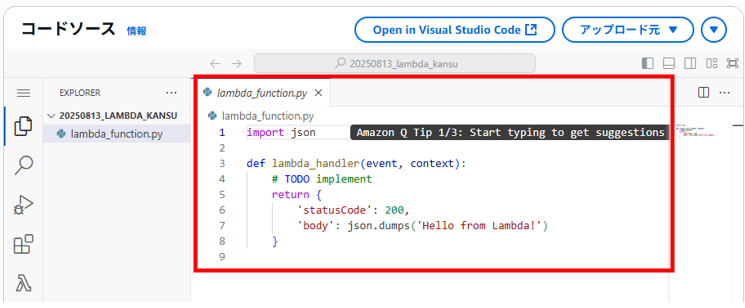
「コード」タブの編集画面が表示されます。
この時点で「lambda_function.py」が作成されて何かコードが記載されています。
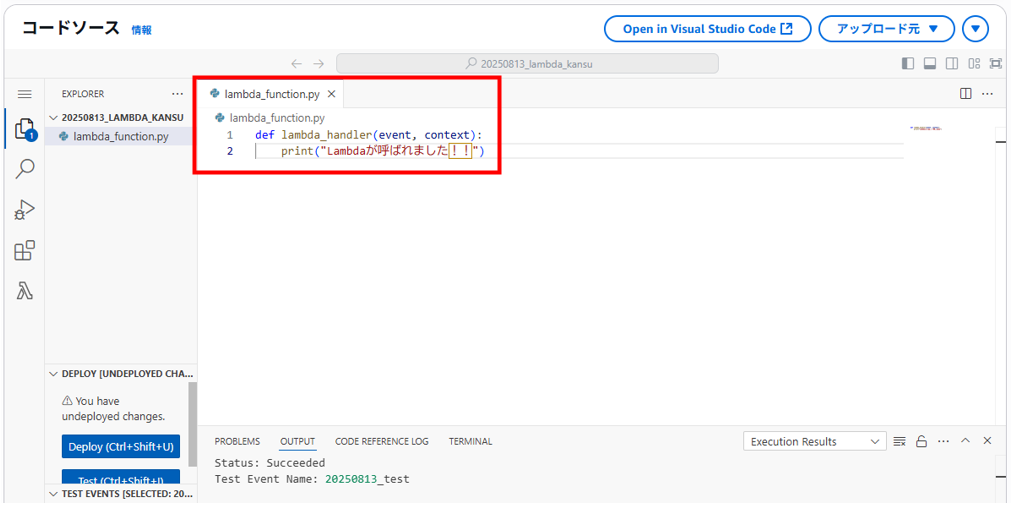
既存のコードを上書きする形で以下2行のコードを入力します。
def lambda_handler(event, context):
print("Lambdaが呼ばれました!!")
コードの内容は 「トリガーイベントが起きたらlambda_handlerが呼ばれ、何かしらprintして終わり」です。 これで最小限の関数が一通り完成です。
編集が終わったら「Deploy」ボタンをクリックします。何度かテストしたのですが「Deploy」を押さないとコードを変更しても反映されませんでした。
2行目の「print」はインデントしてないとエラーになりました。そのあたりPythonのルールを理解してなかったようです。勉強します・・・
Lambda関数のテスト
次に動作の確認です。 Lambdaにはテスト機能があるので、まずはそれで実行してみます。
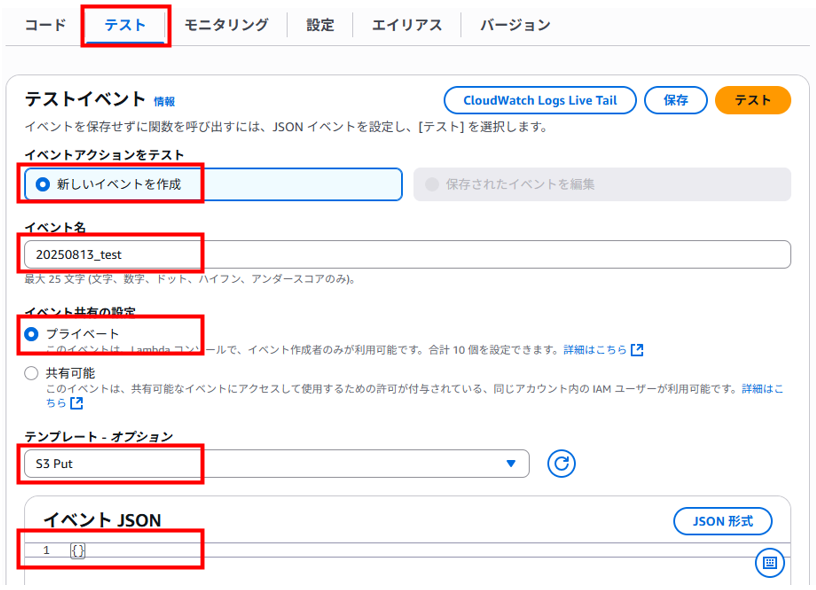
「テスト」タブへ移動して、以下を入力、選択して「保存」をクリックします。
・イベントアクションをテスト:新しいイベントを作成
・イベント名:任意のイベント名(20250813_test)
・イベント共有の設定:プライベート
・テンプレート – オプション:S3 Put
・イベント JSON:{ } のみ(もともとのコードを上書きする)
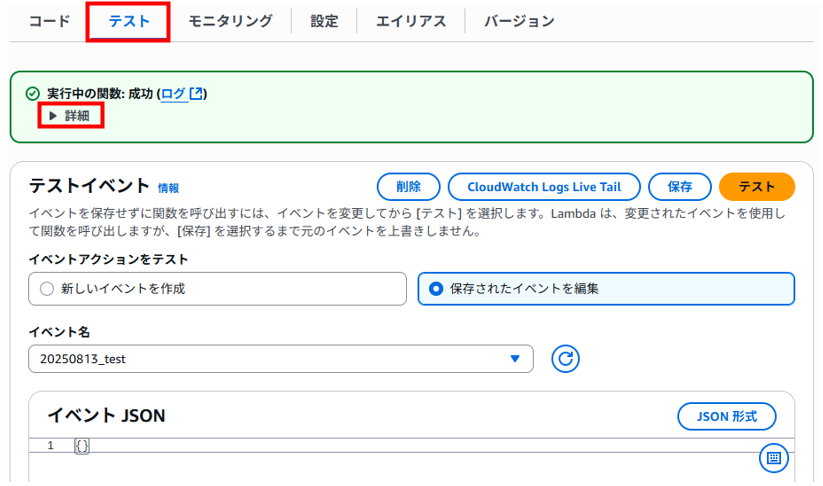
保存が完了したら右上の「テスト」をクリックします。
成功が表示され、詳細を展開します。
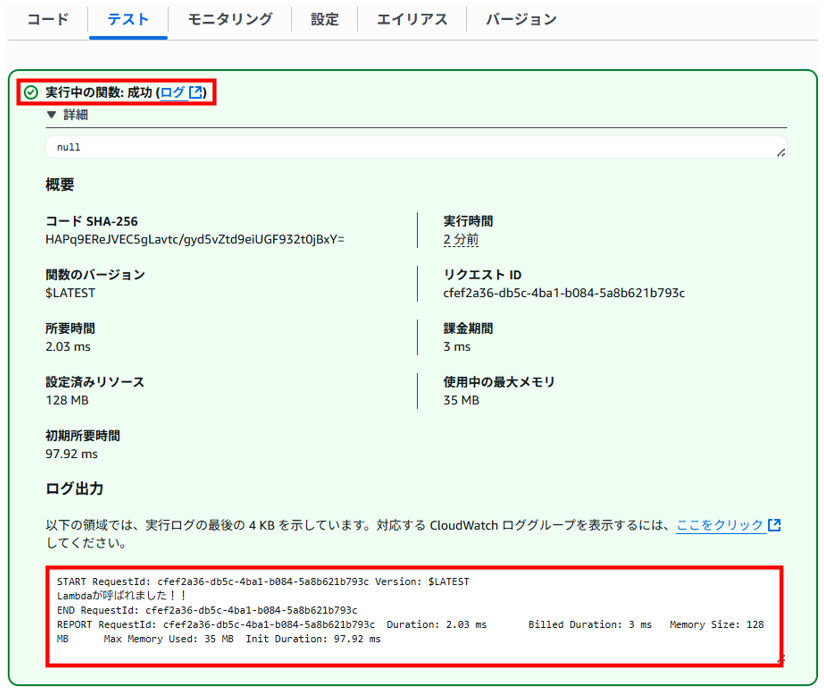
ログの中に「Lambdaが呼ばれました!!」の表示がありました。
また、ログ画面内のリンクからCloudWatch Logsのログを確認することができます。 「実行中の関数:成功(ログ)」のリンクをクリックします。
CloudWatch Logsへ画面が遷移、自動的にロググループ「20250813_lambda_kansu」が作成されていることが確認できます。
ロググループ「20250813_lambda_kansu」の中に「ログストリーム」タブのログのリンクをクリックします。
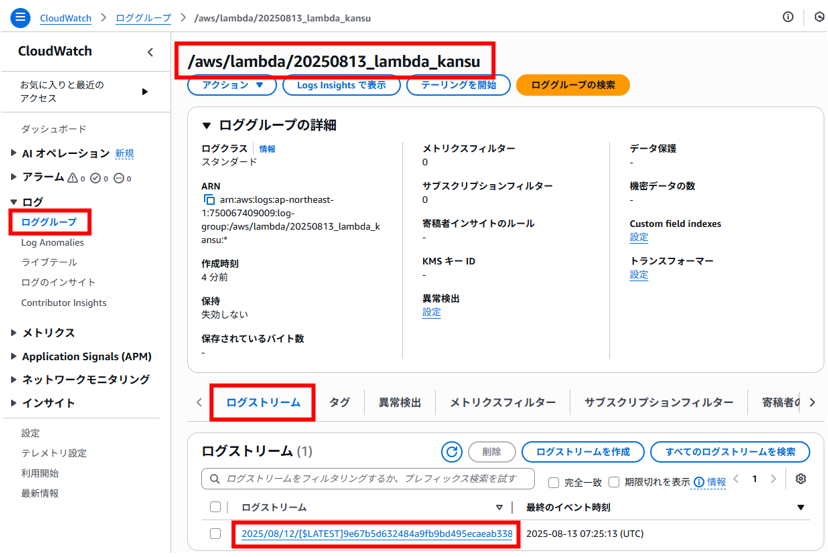
ログイベントが表示され、ここでも「Lambdaが呼ばれました!!」が確認できます。
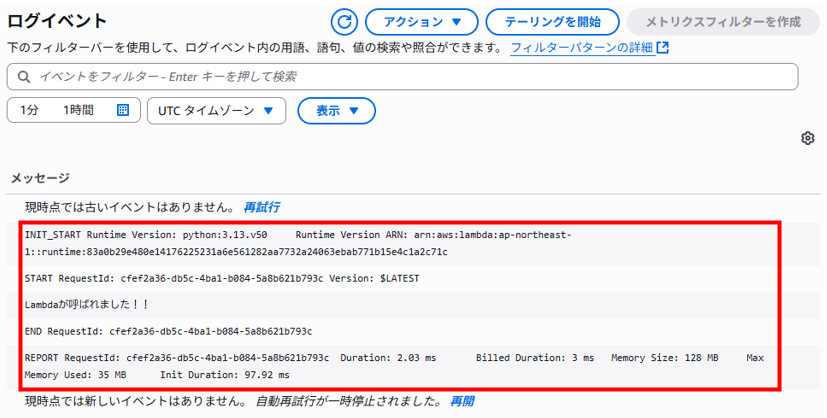
S3にオブジェクト(テキスト)をアップロードしてテスト
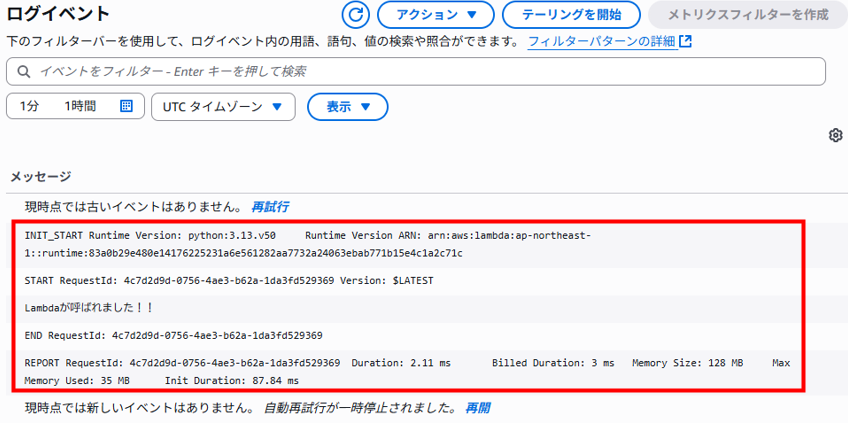
テストだけでは、実際に挙動が確認できた気がしませんので、 実際にトリガーとなる行為を行うことでコードを実行してみます。 今回はマネジメントコンソールからS3にファイルをアップロードしてみます。 トリガーイベント設定に合致した名前のファイルをアップロードします。 「test.txt」をS3バケットの「targets」フォルダ内へアップロードします。
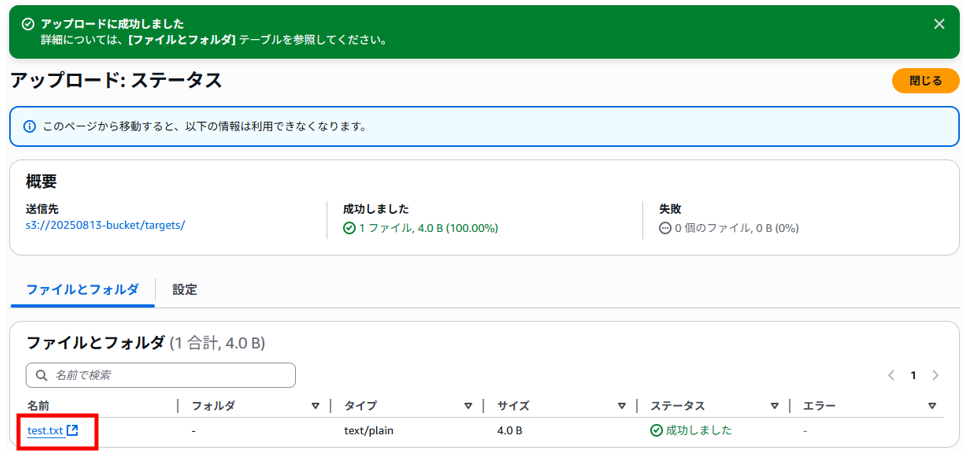
CloudWatch Logsの画面をするとログストリームが1つ追加されました。ログストリームをクリックすると 「Lambdaが呼ばれました!!」の表示が確認できます。
何度か検証した際、ログストリームが作成される場合と作成済みのログストリームの中に追記される場合がありました。
時間がなかったので切り分けできてないですが今後の課題としたいと思います。
これで最小限の関数でLambdaの挙動を確認することができました。
S3にオブジェクト(テキスト)をアップロードしてテスト(オブジェクトの情報を取得する)
先ほどはオブジェクト(テキスト)を置いただけでした。
次は、lambda_handlerに渡された引数eventにはトリガーイベントの情報が含まれているので、 そこから欲しい情報を取り出してみます。
S3のバケット名とオブジェクトのキー(パス)を取得する場合は以下のようなコードを書きます。
(このコードも参考サイトからそのまま引用させていただきました。先ほどと同じように2行目以降はインデントを下げてください。)
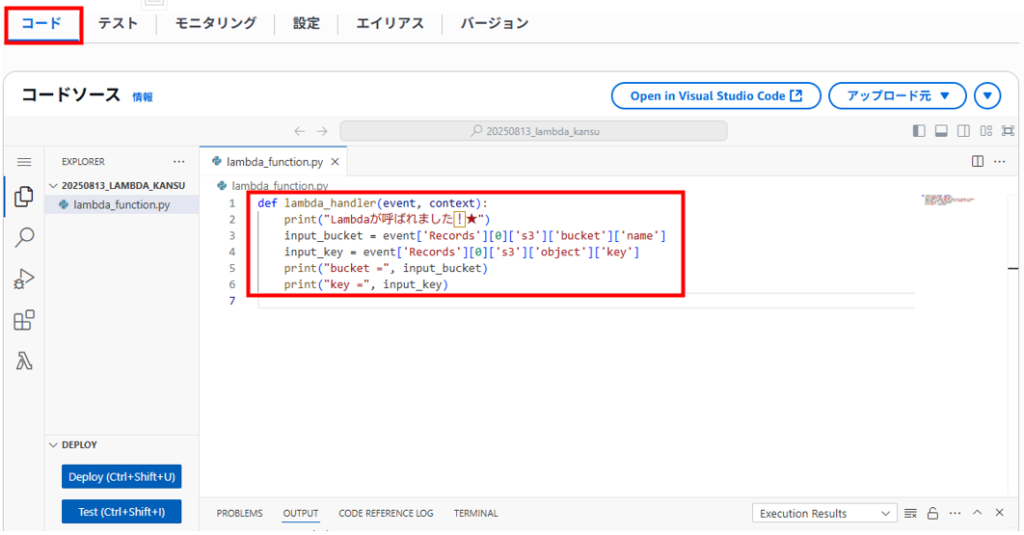
「コード」タブへ移動し、先ほど2行だけ書いたコードを上書きして「Deploy」をクリックします。
def lambda_handler(event, context):
print("Lambdaが呼ばれました!★")
input_bucket = event['Records'][0]['s3']['bucket']['name']
input_key = event['Records'][0]['s3']['object']['key']
print("bucket =", input_bucket)
print("key =", input_key)
S3バケットへオブジェクト(テキスト)をアップロードしてCloudWatch Logsのログストリームを確認します。
ログイベントにbucket名とアップロードされたテキストファイル名(ccc.txt)も出力されていることがわかります。
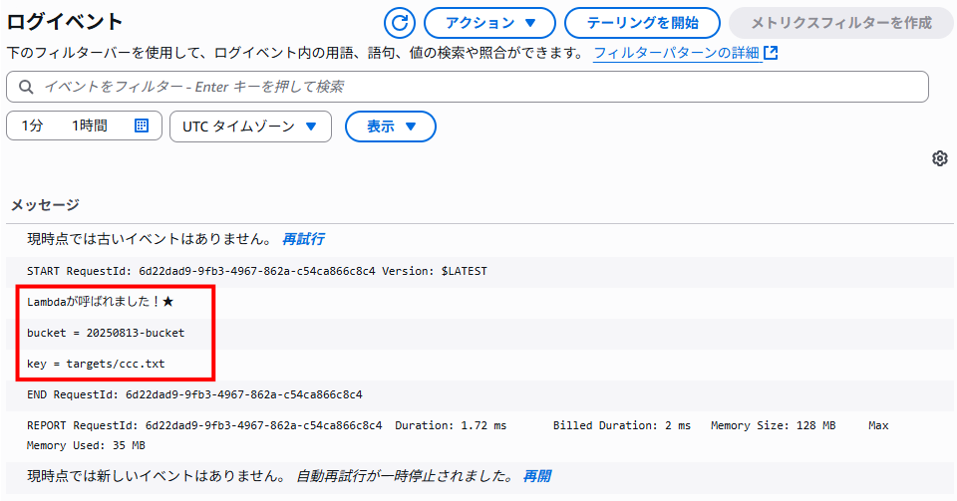
この時点でIAMロールの設定なしにS3バケットの情報を取得できています。
参考サイトに記載されていたことですが、これはLambda関数がS3バケットへアクセスしているわけではなく、トリガーイベントから通知された情報をLambda関数が受け取っているだけと理解すればよいそうです。
S3のファイルをコピーする関数を作る
S3バケットへアップロードしたオブジェクト(テキスト)をコピーして別のフォルダ(パス)に出力してみます。
今回はコピーするためにLambdaがS3バケットへアクセスする必要が出てくるのでIAMロールでポリシーを追加してアタッチします。
S3バケットのtargetsフォルダへ aaa.txt をアップロードした後、Lambda関数が実行されて
aaa.txt をS3バケットのoutputsフォルダへコピーするという流れになります。
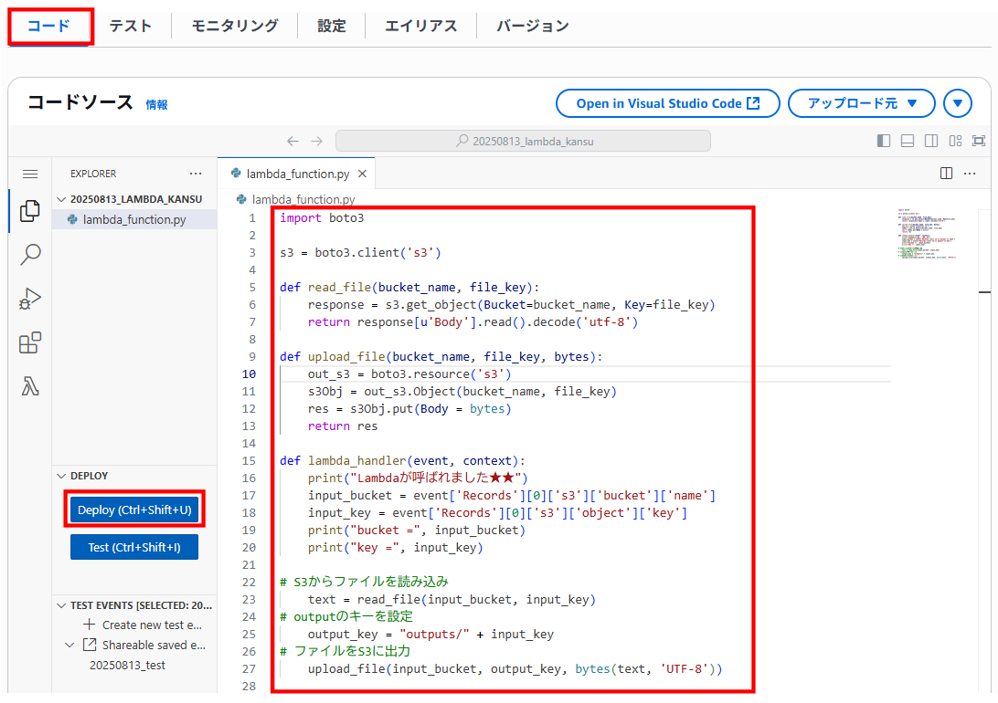
コードの変更
これもまるまる参考サイトから引用しています。
import boto3
s3 = boto3.client('s3')
def read_file(bucket_name, file_key):
response = s3.get_object(Bucket=bucket_name, Key=file_key)
return response[u'Body'].read().decode('utf-8')
def upload_file(bucket_name, file_key, bytes):
out_s3 = boto3.resource('s3')
s3Obj = out_s3.Object(bucket_name, file_key)
res = s3Obj.put(Body = bytes)
return res
def lambda_handler(event, context):
print("Lambdaが呼ばれました★★")
input_bucket = event['Records'][0]['s3']['bucket']['name']
input_key = event['Records'][0]['s3']['object']['key']
print("bucket =", input_bucket)
print("key =", input_key)
# S3からファイルを読み込み
text = read_file(input_bucket, input_key)
# outputのキーを設定
output_key = "outputs/" + input_key
# ファイルをS3に出力
upload_file(input_bucket, output_key, bytes(text, 'UTF-8'))
コードタブで上書きして「Deploy」をクリックしてコードを更新します。
作成したIAMロールを編集
AWSマネジメントコンソールで「iam」を検索します。
左ペインのロールをクリックし、画面中央で事前に作成していた「20250813_lambda_Role 」をクリックします。
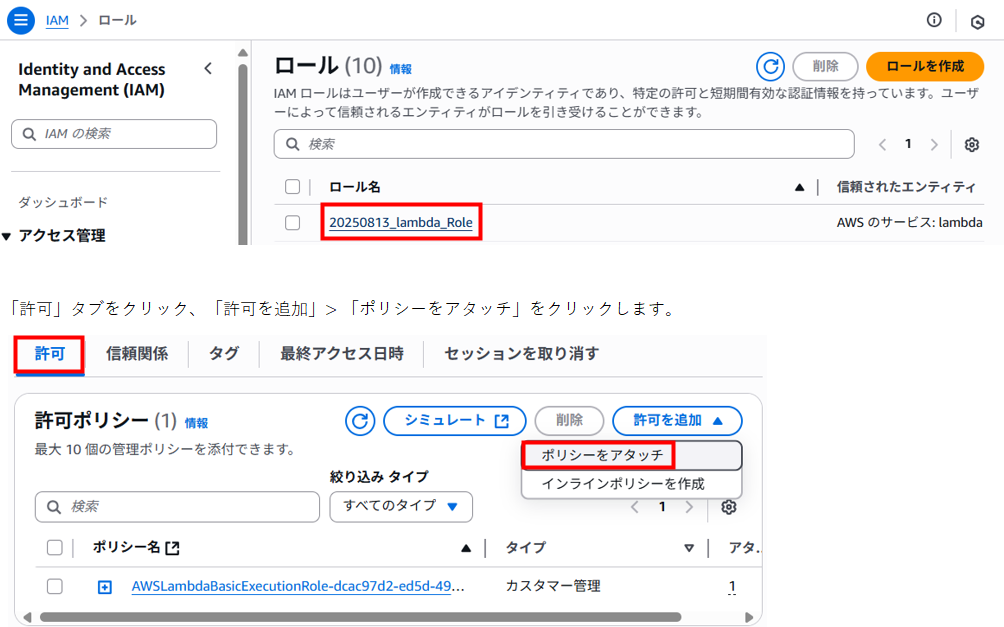
「AmazonS3FullAccess」を検索、チェックを入れて「許可を追加」をクリックします。
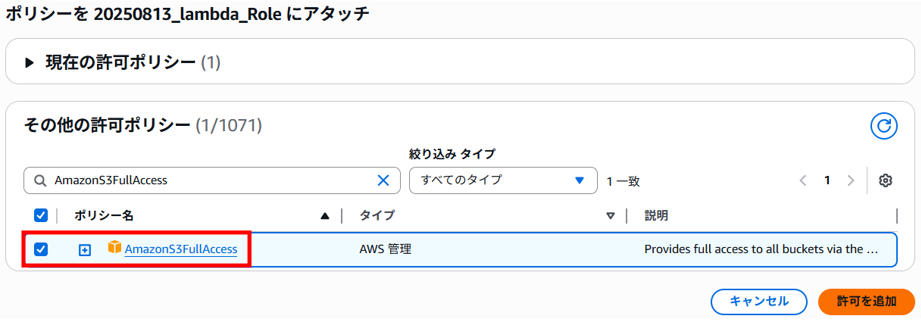
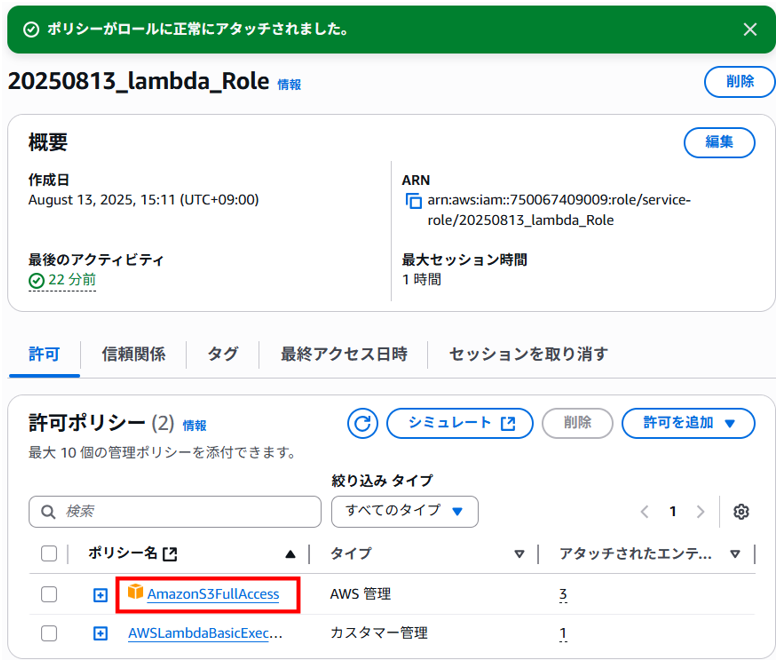
ロールへポリシー「AmazonS3FullAccess」がアタッチされました。
Lambda関数のページに戻りトリガーの「S3」をクリックします。
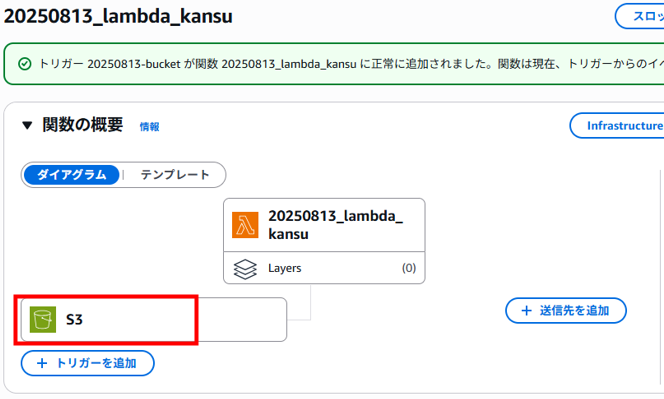
「設定」タブが表示されます。(S3バケット名が変更されていますが気にしないでください・・・)
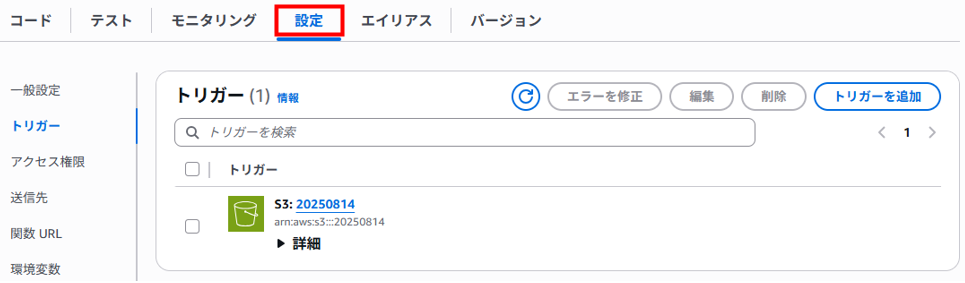
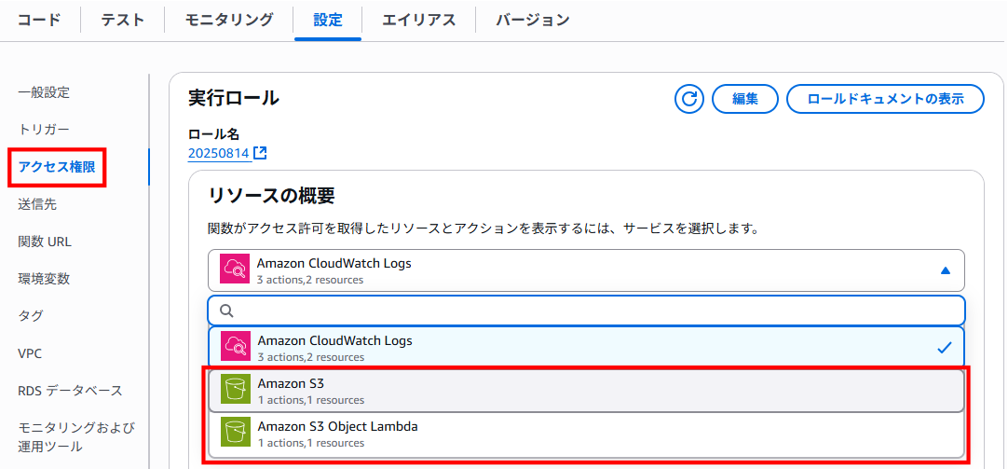
左ペインの「アクセス権限」をクリックします。
「リソースの概要」のプルダウンを展開するとIAMロールでポリシーをアタッチしたS3に関する情報が追加されていることが確認できます。
ちなみに「Amazon CloudWatch Logs」に対するアクセス権限は、Lambda関数を作成した時点でデフォルト設定されるそうです。
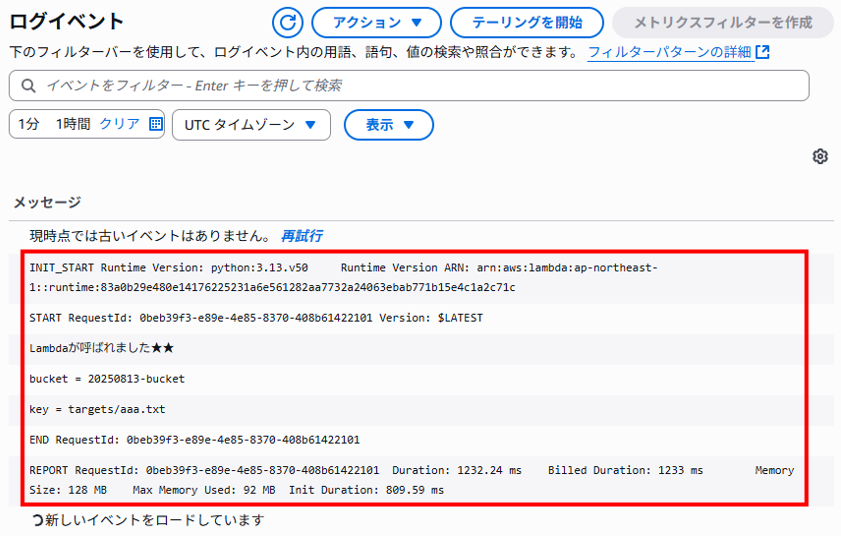
S3にオブジェクト(テキスト)をアップロードしてテスト(オブジェクトをコピーする)
S3バケットへオブジェクト(テキスト)をアップロードしてCloudWatch Logsのログストリームを確認します。
ログイベントにbucket名とアップロードされたテキストファイル名が出力され、エラーが出てないことが確認できました。
※余談ですが、特にコードを変更してないのですが成功するまで何度もリトライしたり、あれやこれやしました。ただ、なぜ最終的に成功したかまでは特定できませんでした。
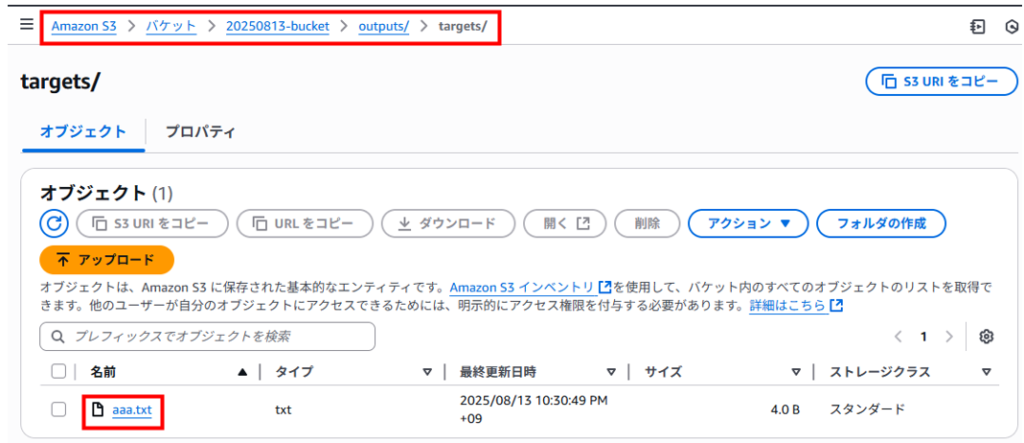
S3バケットの outputs/targets フォルダ内を確認すると targetsフォルダへアップロードした aaa.txt がコピーされて存在することが確認できました。
検証後のリソースの削除
簡単にですが、作成したリソースの削除について記載します。
S3バケット
・ファイルの削除
・バケットの削除
CloudWatch
・ロググループの削除
IAMロール
・作成したロールの削除
Lambda
・作成した関数の削除
まとめ
Lambdaについて、実際手を動かすことで少し理解が深まりました。ですがコードタブとテストタブの関係性などまだまだ疑問に思うところが多々あります。そのあたりはこれから検証を進めて理解できればと考えています。
あと、Pythonのコードももっと勉強していきたいとあらためて思いました。
以下、他の記事をまとめた一覧です。AWSもまとめています。

