【AWS_44】Amazon AthenaからS3バケット上のデータをクエリする

Amazon Athena について机上の勉強だけで理解できてないため、検証してみたいと思います。
検証内容として、S3バケットにアップロードしたCSV形式のデータに対してAmazon Athenaから直接クエリしてデータを確認してみます。
今回、クエリ結果は別のS3バケットへ出力されるように設定しています。
Amazon Athenaは「標準的なSQLを使ってAmazon S3のデータを直接クエリすることができる」サービスです。サーバレスで実行可能なのでインフラの構築が必要無くすぐに使用する事ができ、Athenaは実行されたクエリに対してのみ料金がかかります。
以下サイトを参考にさせていただきました。ありがとうございます。
【初心者向け】AthenaからクエリしてS3上のデータを取得してみた
https://dev.classmethod.jp/articles/get_s3data_by_athena/
目次
CSVファイルを作成
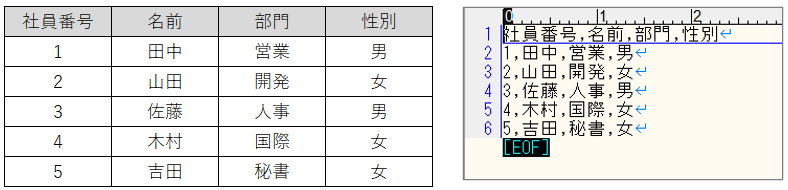
以下データを入力したCSVファイルを作成します。ファイル名は、syain.csvとしています。
S3バケットを作成してCSVファイルを保存
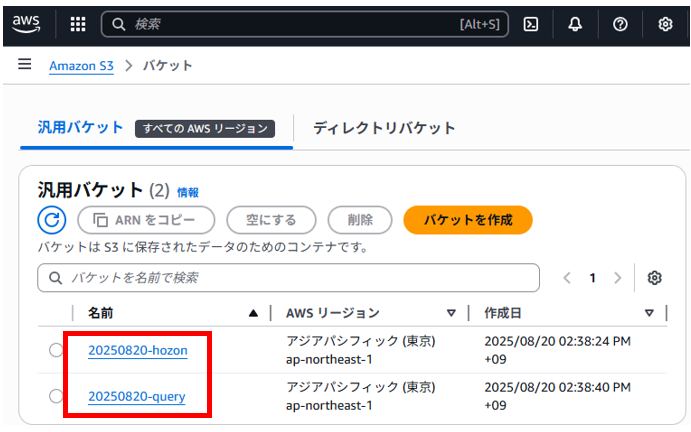
CSVファイルを保存しておくS3バケットとAthenaからクエリした結果をデータとして保存する2つのS3バケットを作成します。
※S3バケットの作成については、以下を参照してください
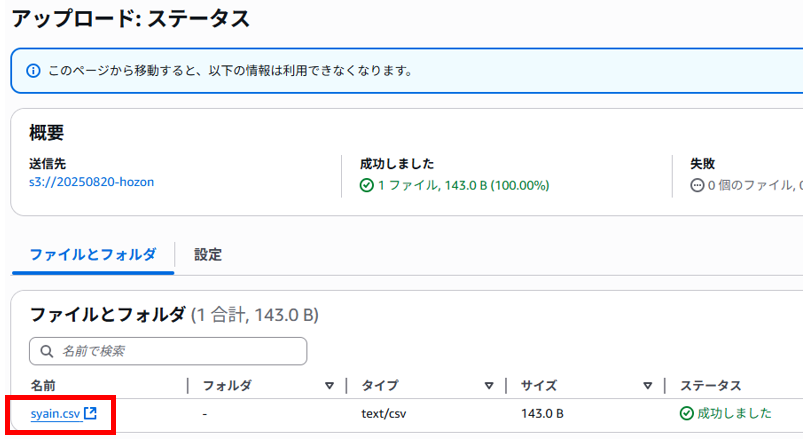
作成したS3バケットの「20250820-hozon」へCSVファイルをアップロードしておきます。
Athena側の設定
Athena側の設定ではクエリエディタの機能からデータベースとテーブルを作成してクエリを出せる環境を作ります。
AWSマネジメントコンソールで「athena」を検索します。
左ペインのクエリエディタをクリックすると画面中央にクエリエディタが表示されます。
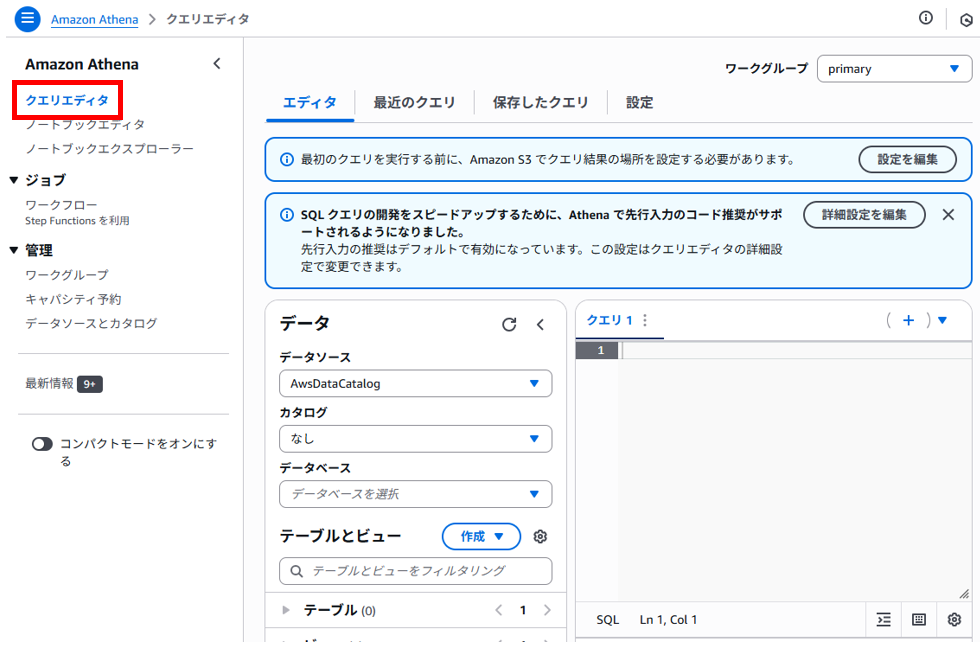
クエリ結果の保存先設定
クエリ結果の保存先を設定していない場合、先にS3バケットを保存先として設定する必要があります。
下の画面の設定タブから設定画面に遷移します。
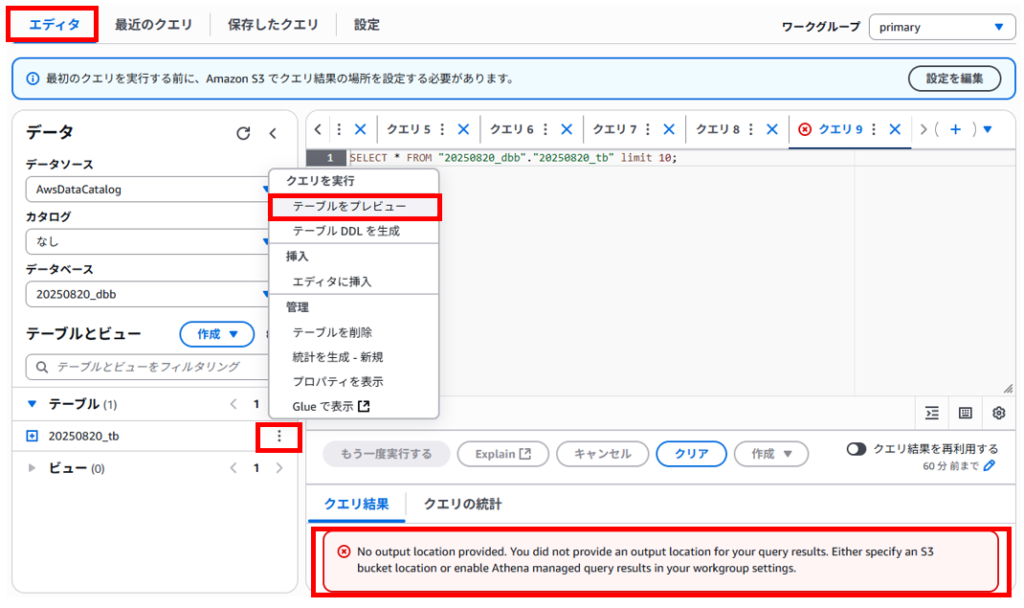
※この設定をせずにクエリを出すと以下のエラーが表示され、クエリに失敗します。エラーメッセージを訳してみると「出力場所が指定されていません。S3 バケットの場所を指定するか、ワークグループ設定で Athena マネージドクエリ結果を有効にしてください。」とあります。Athena マネージドクエリ結果を有効にすればS3バケットの場所を指定しなくてもよさそうなので本記事の最後で検証しましたので参考にいただければと思います。
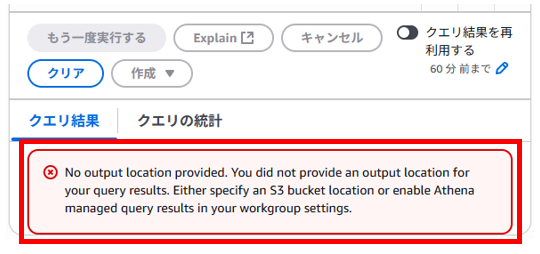
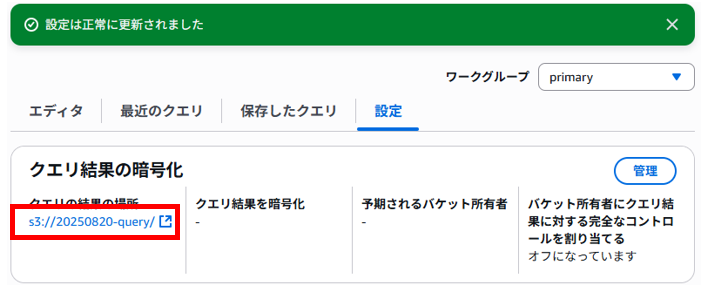
「設定」タブ > 「管理」をクリックします。
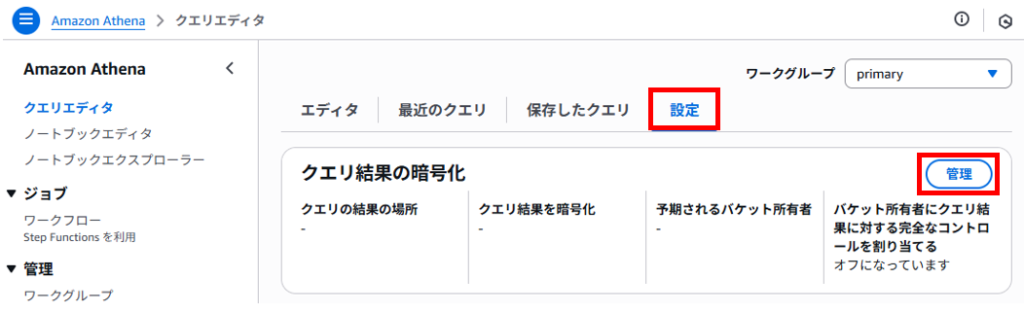
事前準備で作成したクエリした結果を保存するS3バケット(20250820-query)を「Browse S3」ボタンから指定して「保存」をクリックします。
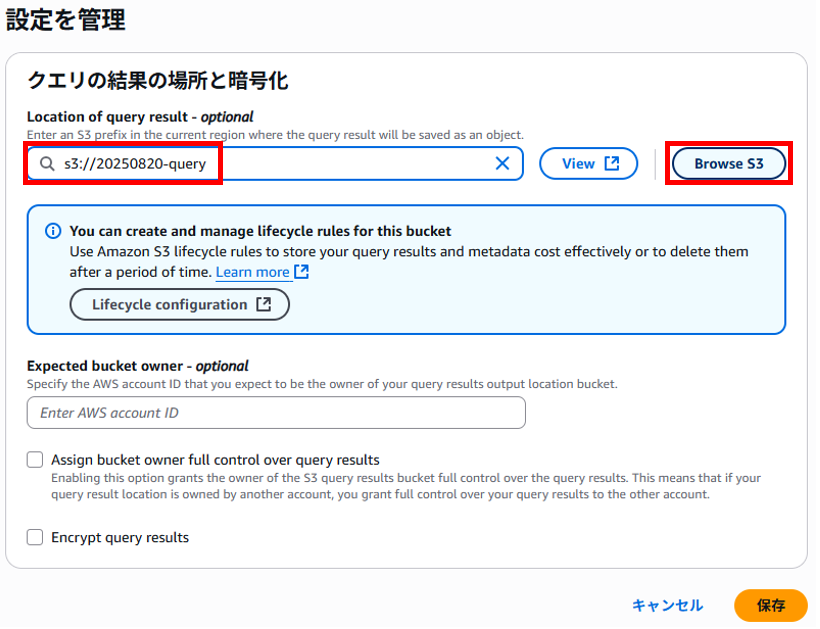
クエリした結果を保存するS3バケット(20250820-query)が登録されました。
これでクエリ結果の保存先のバケットの設定ができました。
クエリエディタの設定(データベース、テーブルの作成)
クエリを出す環境を作るにあたってテーブルの作成が必要となります。
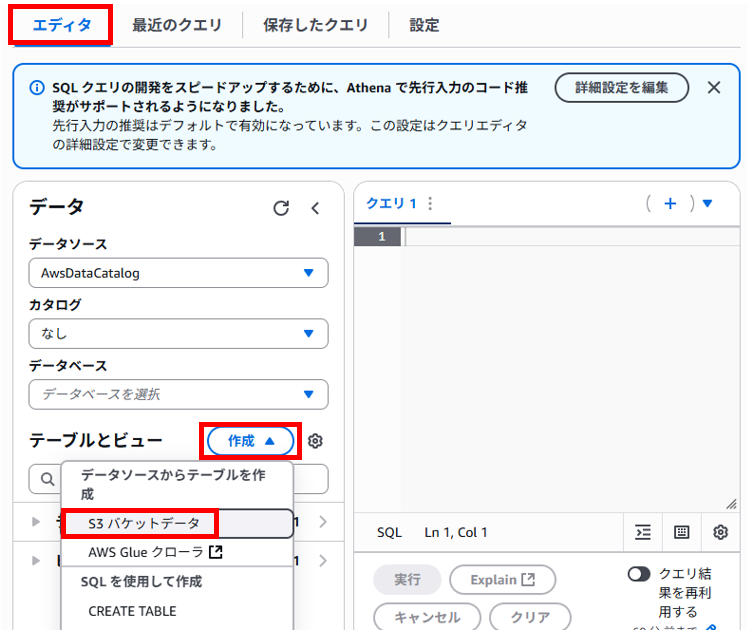
「エディタ」タブへ移動します。
「テーブルとビュー」の横にある「作成」を展開し、「S3バケットデータ」を選択します。
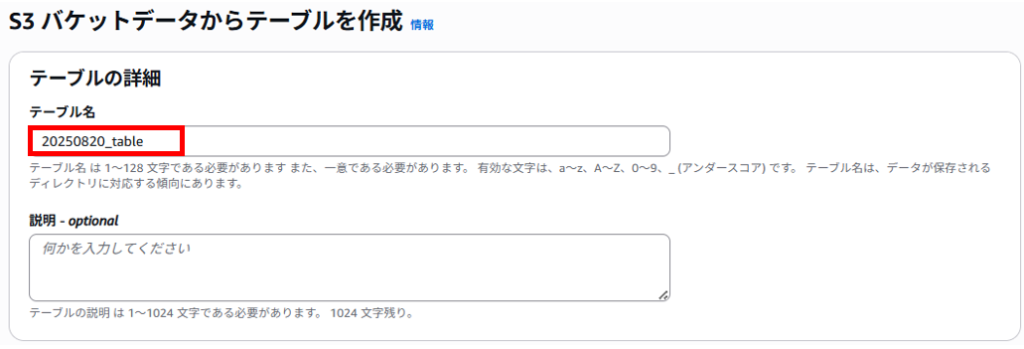
遷移した画面でテーブル名の指定やデータベース名の指定などテーブル作成の設定を行います。
テーブル名は、任意のテーブル名を入力します。テーブル名は一意である必要があります。
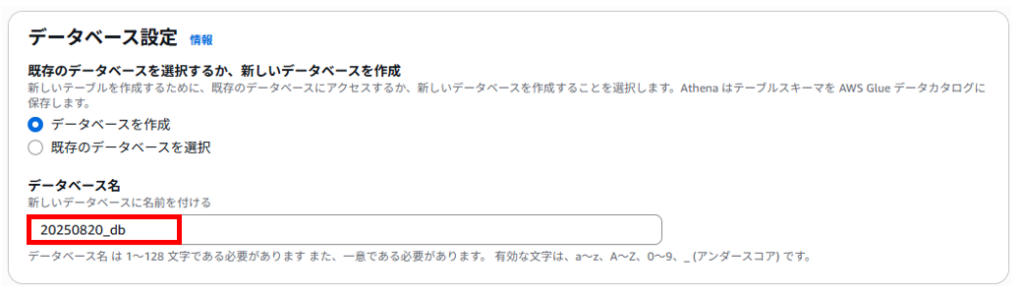
データベースは新規に作成するので「データベースを作成」を選択します。
データベース名は、任意のデータベース名を入力します。データベース名も一意である必要があります。
クエリの対象となるデータを指定します。事前にS3へ保存したCSVファイルの入っているバケット名を指定します。
※CSVファイルではなく、バケット名を選択します。CSVファイルは選択できないので注意してください。

データの形式を指定します。クエリ先のデータ形式はCSVですのでCSVを選択します。その他はデフォルトとします。
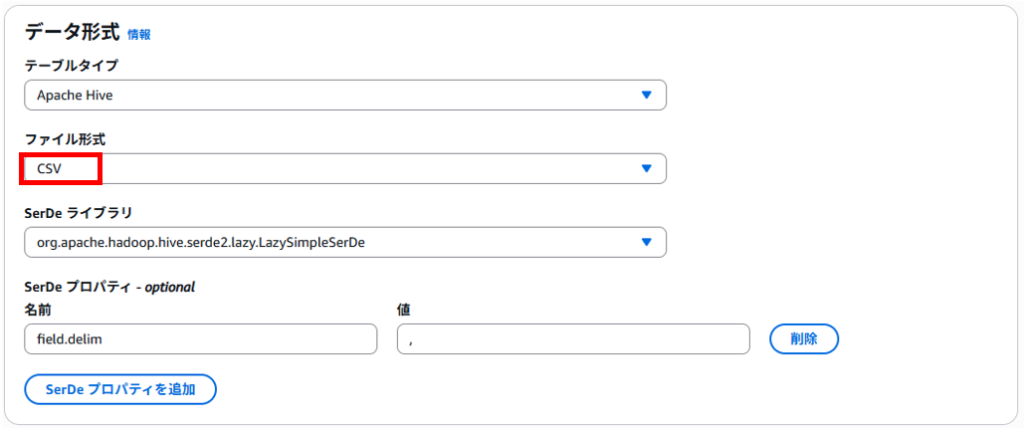
テーブルにデータの列名を設定します。「列を追加」ボタンで列名を追加できます。またデータ型もここで指定します。
「説明」は任意です。今回は入力してみました。
※列名は、アップロードしたCSVファイルの列名と同じである必要はないですが、意味が同等でないとSQLクエリで表示した際、列名と値の関係が一致しないものになるので注意してください。
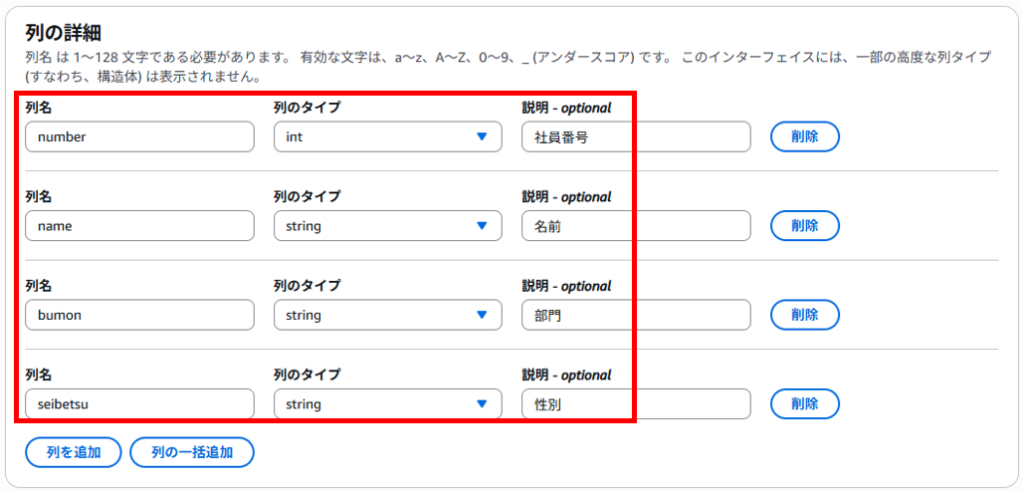
その他の項目はデフォルトのままとし、右下の「テーブルを作成」をクリックします。
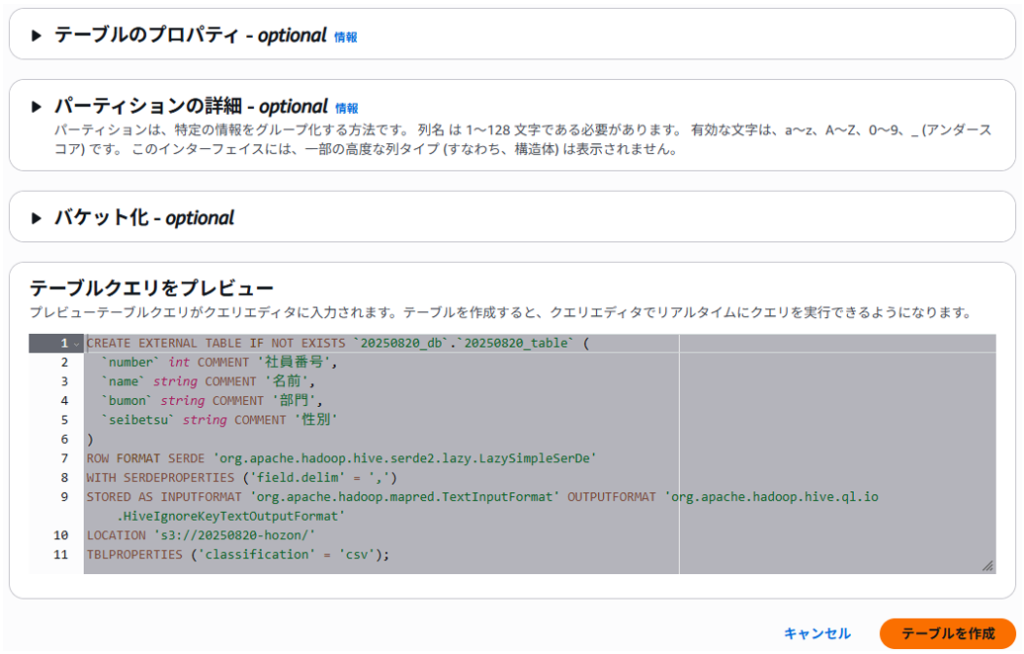
データベースやテーブルが作成されました。
(おそらくクエリ2タブのSQLが実行されたのかなと思います)
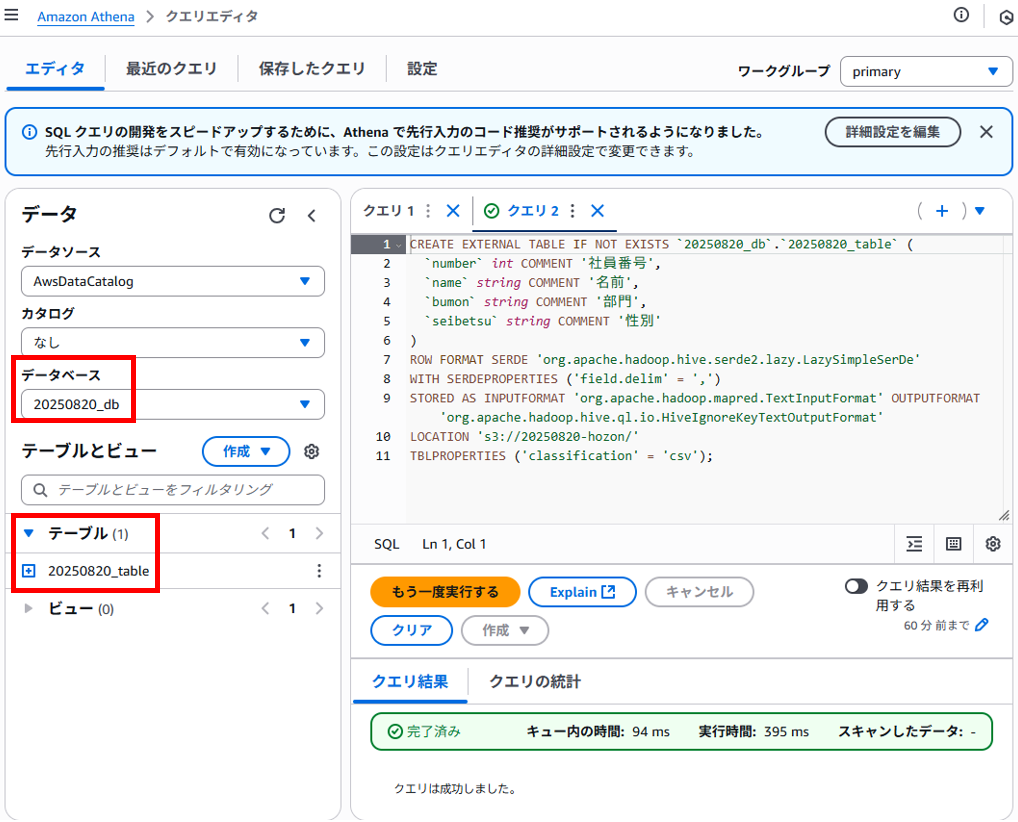
SQLクエリでS3からデータを取得する
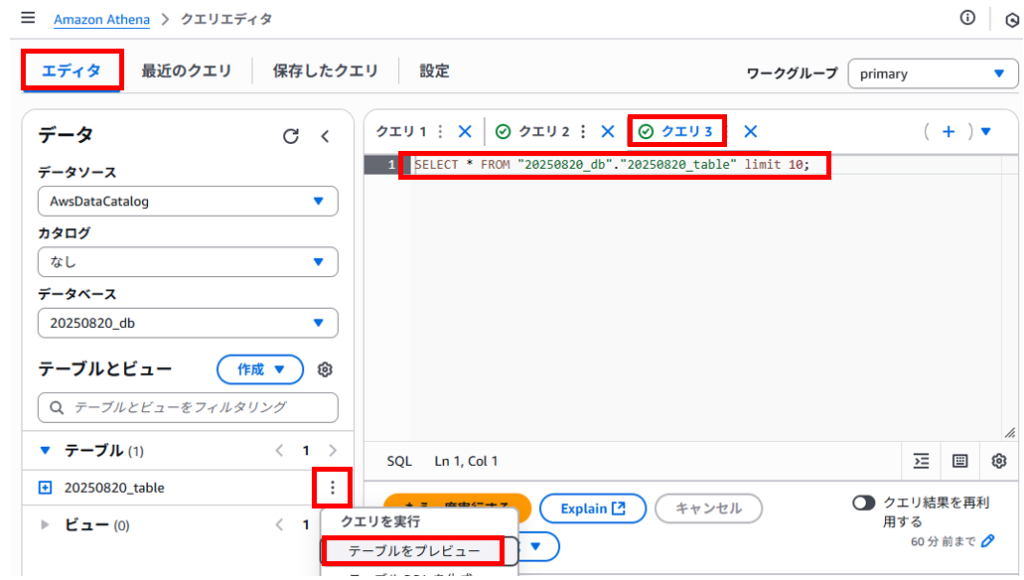
「エディタ」タブ > クエリエディタの画面に戻り、作成したテーブル名の右にある3点ボタンメニューの「テーブルをプレビュー」を押すとSELECT文のクエリが作られて実行されます。
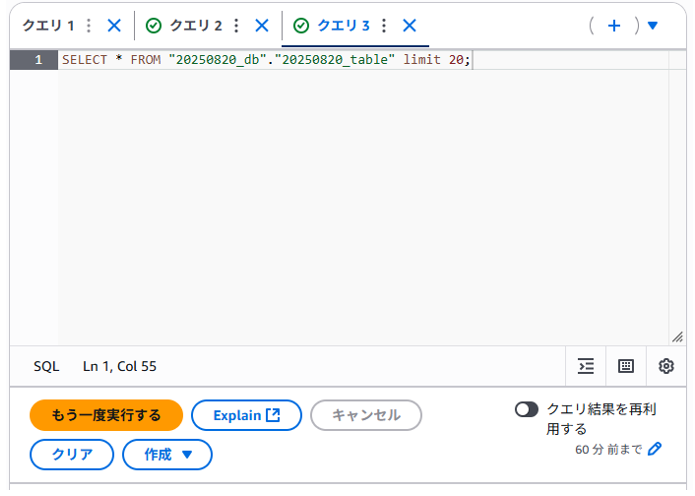
「クエリ3」タブにSELECT文が作成されていました。LIMIT句はSELECT文でレコードを取得する際の行数を制限するために使用されるようです。
ちなみに「クエリ3」タブのSELECT文は書き直して再実行し直すことが可能です。あくまで以下の文はサンプルとして作成されたものとなります。
SELECT * FROM “20250820_db”.”20250820_table” limit 10;
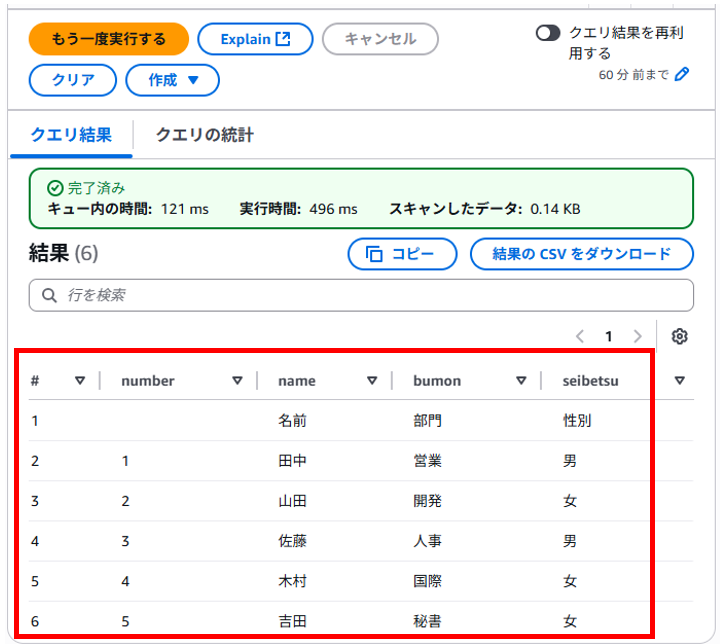
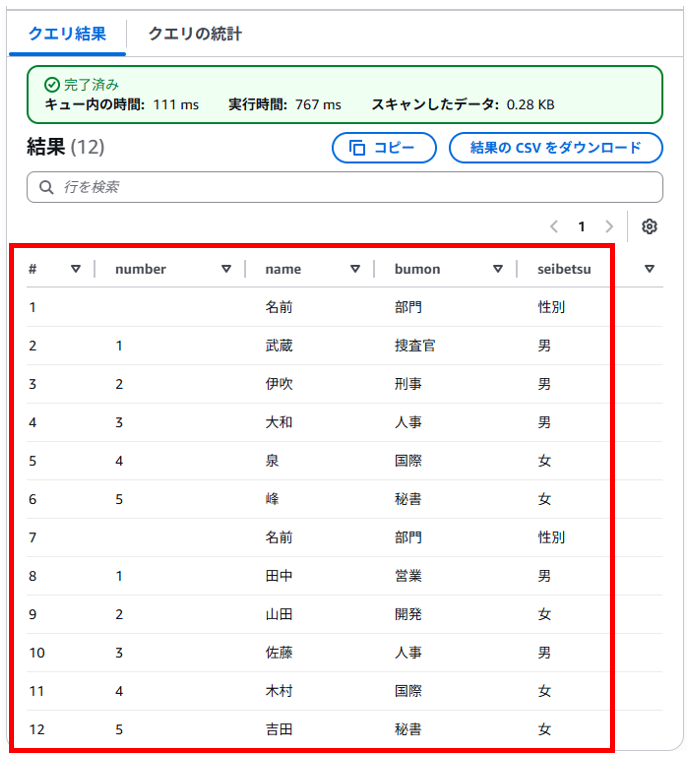
画面を下へスクロールすると実行結果が表示されていました。
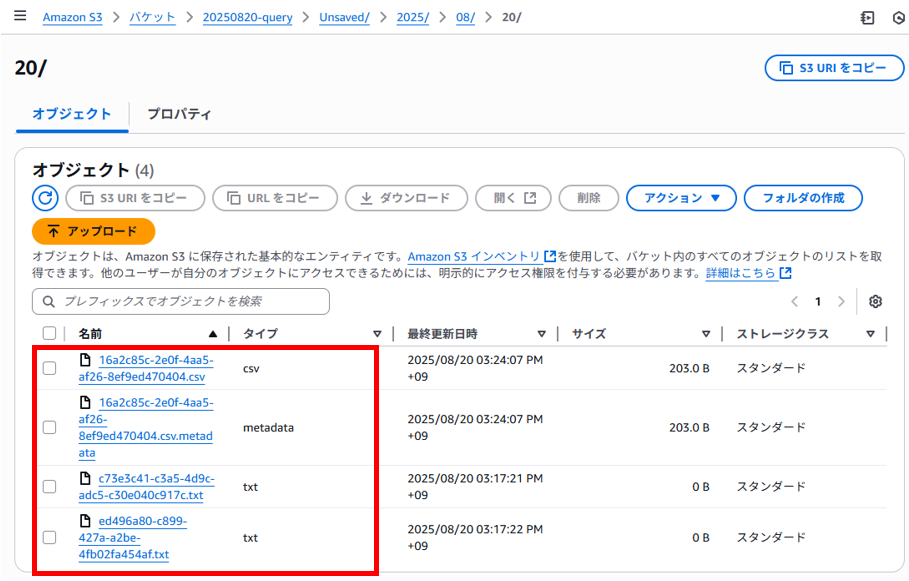
クエリした結果の保存先(S3バケット)を確認
クエリした結果を保存するS3バケット(20250820-query)を確認すると以下のようにCSVファイルやTXTファイルが作成されていました。
TXTファイルの中身は空でしたがCSVファイルの中身はSQLクエリの結果でした。
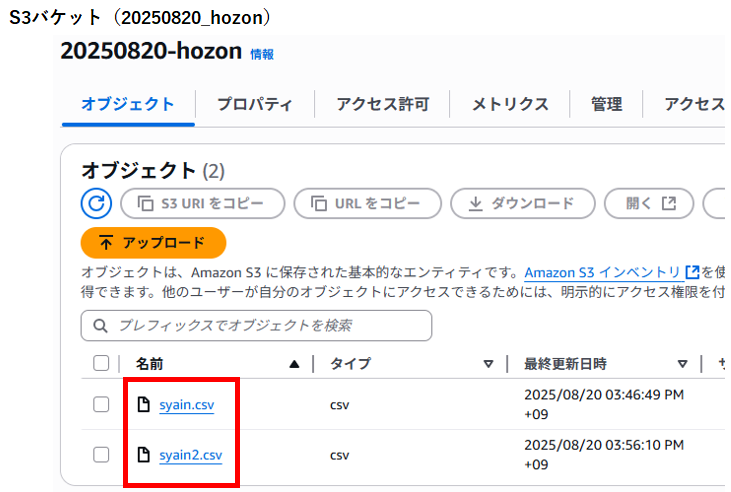
S3バケットへ出力されたCSVファイルの内容は、AthenaでSQLクエリした際の結果と同じでした。

気になったこと1(どこのデータにSQLクエリしているのか)
ここまでの手順でAthenaにデータベースとテーブルを作成し、SQLクエリを実行して結果を確認しました。
私が気になったのは、Athenaに作成したテーブル内にCSVファイルの値が取り込まれて、Athena内のテーブルに対してSQLクエリをしているのかなということでした。
検証としてS3バケット内にアップロードしていたCSVファイルを削除してAthenaでSQLクエリを実行したところ、SQLクエリの実行自体は成功しましたが値は何も返されませんでした。その後、あらためてS3バケットへCSVファイルをアップロードしてからSQLクエリを実行すると値が返されました。
以上より、S3バケット内のCSVファイルのデータをAthenaへ取り込んでいるわけではなく、参照しているだけということが確認できました。
気になったこと2(元データが複数ある場合)
S3バケット内へヘッダ情報が同じで値が異なるCSVファイルをもう1つアップロードしたらSQLクエリを実行するとどのような結果が返されるのか試してみました。

SQLクエリを実行したところ、S3バケットにアップロードした2つのCSVファイルに対する結果が返されました。
運用する場合は、S3バケットへアップロードするCSVファイルの保存方法についても検討する必要があるのかなと感じました。
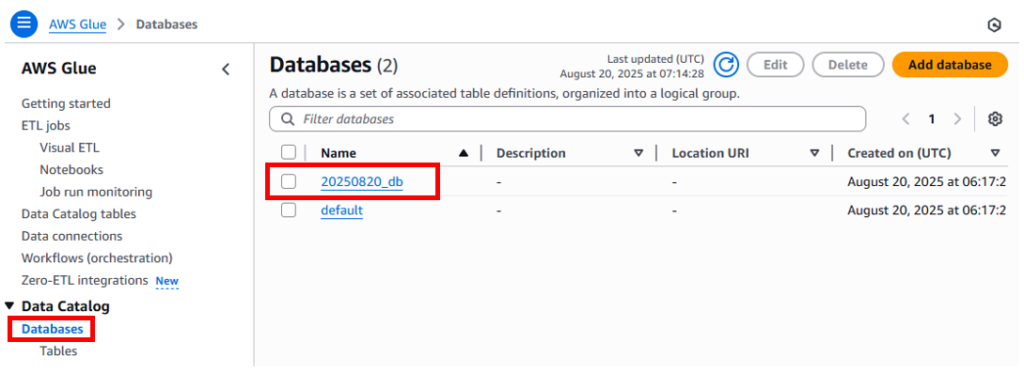
テーブル、データベースの設定内容はGlueに登録されます
先程作成したテーブル及びデータベースの内容はAmazon Glueで確認できます。
AWSマネジメントコンソールで「glue」を検索します。
左ペインのdatabasesをクリックすると画面中央にAthenaで作成したデータベースが表示されます。
ここからデータベースを削除することができます。
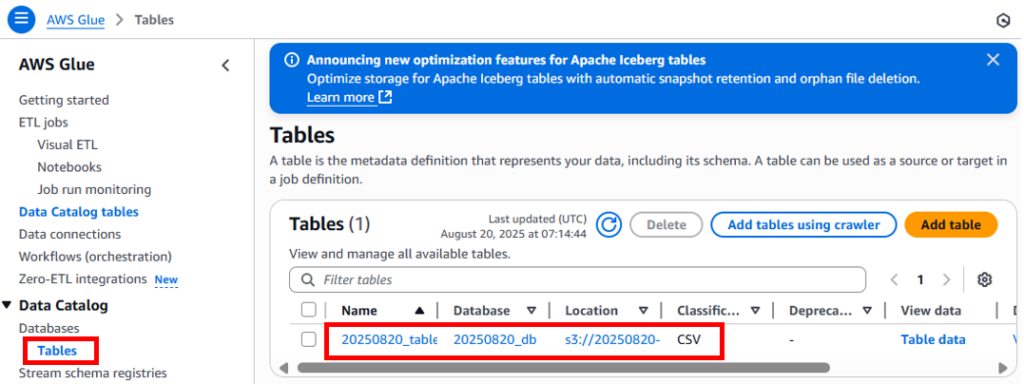
さらに左ペインのTablesを選択すると画面中央にAthenaで作成したテーブルが表示されます。
テーブルもここから削除することができます。
【おまけ】Athena マネージドクエリ結果を有効にする
「クエリ結果の保存先設定」でも記載しましたが、クエリ結果の保存先であるS3バケットを設定してない状態で
SQLクエリを実行するとエラーになります。結果を保存する場所がないからです。
ただエラーメッセージには、Athena マネージドクエリ結果を有効にすればS3バケットを指定する必要はないとあったので検証してみました。
くどくなりますが、結果を保存する場所がない状態で「テーブルをプレビュー」をクリックしてSQLクエリを実行すると以下のようなエラーが表示されます。
AWS Management Consoleにログインし、Athenaサービスを開きます。
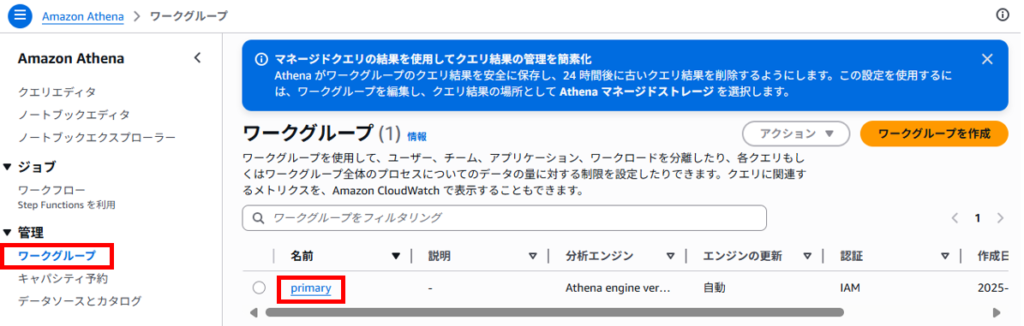
左側のナビゲーションペインから「ワークグループ」を選択し、設定を変更したいワークグループをクリックします。
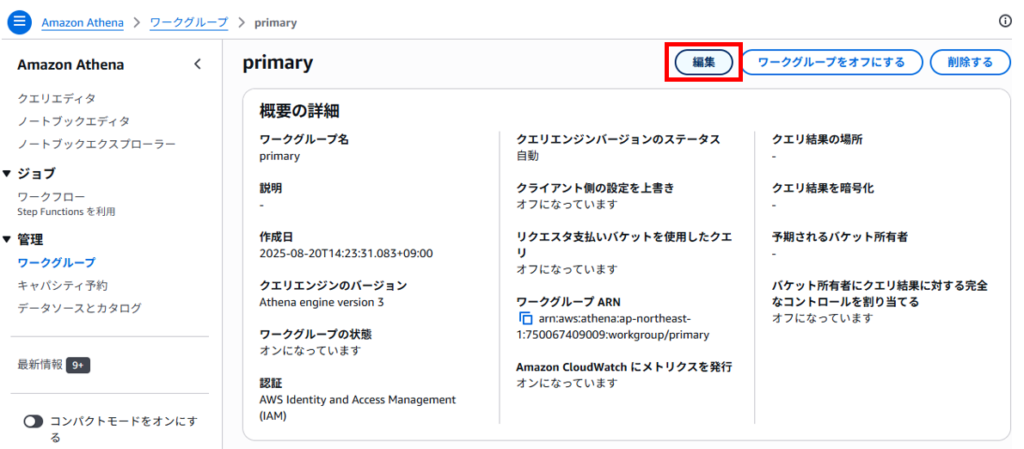
「編集」をクリックします。
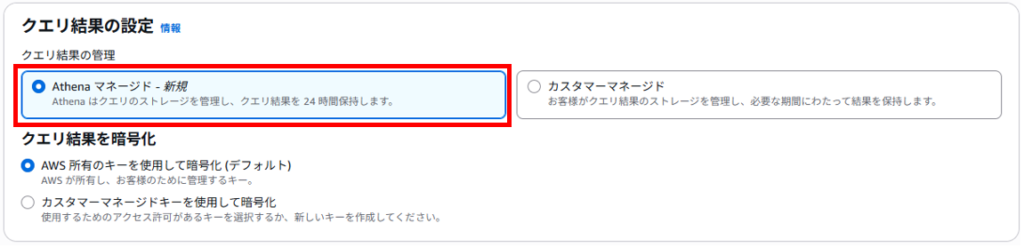
「クエリ結果の設定」画面で「Athenaマネージド-新規」を選択し、右下の「変更を保存」をクリックします。
ワークグループの設定が更新され「クエリ結果の場所」と「クエリ結果を暗号化」の情報が更新されました。
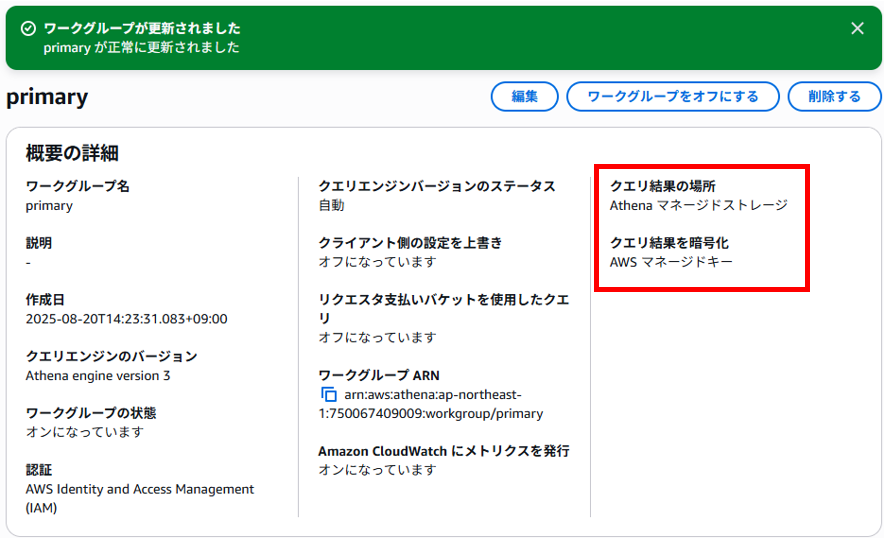
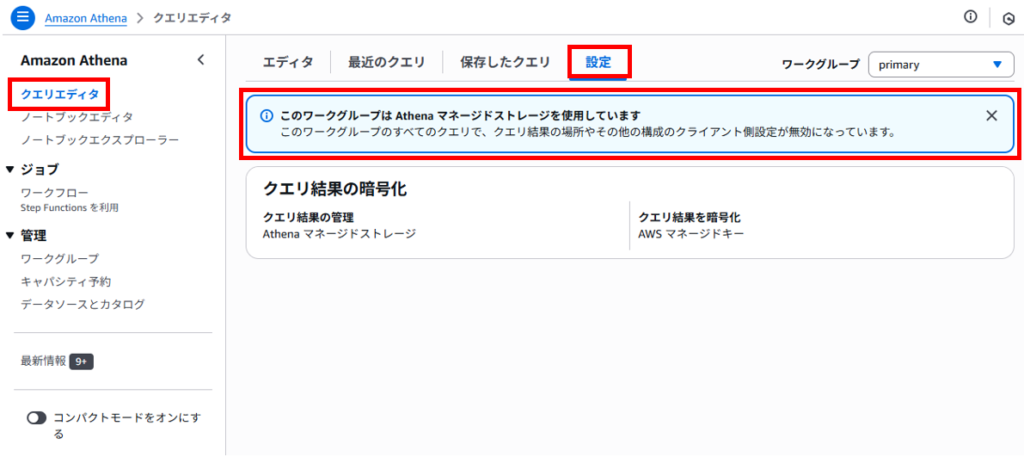
左ペインで「クエリエディタ」を選択、「設定」タブへ移動すると「このワークグループはAthenaマネージドストレージを使用しています」と表示され、設定が編集できなくなっていました。
これで「Athena マネージドクエリ結果を有効にする」の設定は完了です。
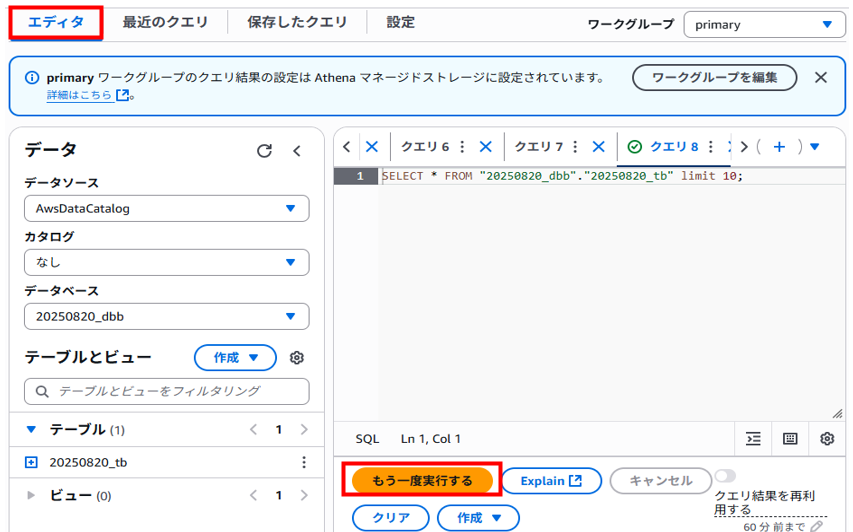
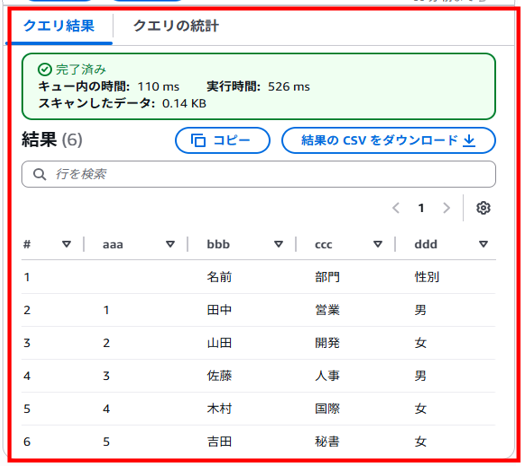
「エディタ」タブへ戻り「もう一度実行する」をクリックするとSQLクエリが実行され、結果が表示されることが確認できました。
検証が確認できた後は、設定を元に戻しておきます。
左側のナビゲーションペインから「ワークグループ」を選択し、設定を変更したいワークグループをクリックします。
「編集」をクリックします。
「クエリ結果の設定」画面で「カスタマーマネージド」を選択し、右下の「変更を保存」をクリックします。
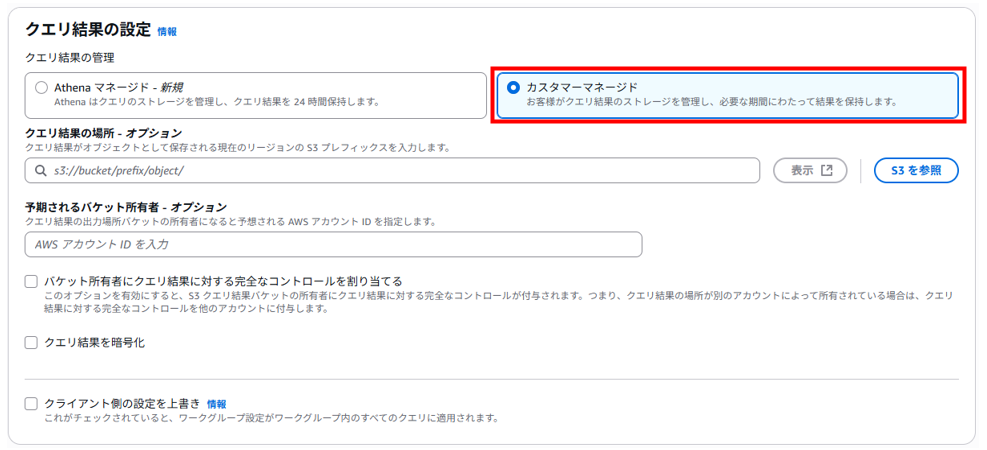
検証後のリソースの削除
簡単にですが、作成したリソースの削除について記載します。
・S3バケット
ファイルの削除
バケットの削除
・Glue
テーブルの削除
データベースの削除
・Athena
※確認のみ
テーブルが削除されていることを確認
データベースが削除されていることを確認
まとめ
Athenaを検証してみることで机上だけでは理解できなかったことや新たな疑問も解消されました。
今回は1つのパターンだけを実施してみましたが、今後も勉強して幅を広げていけたらと思います。
以下、他の記事をまとめた一覧です。AWSもまとめています。

